Afronding migratie IBM Spectrum Protect (TSM) naar IBM Spectrum Protect Plus. Interconnect heeft afscheid genomen van IBM Spectrum Protect (daarvoor Tivoli Storage Manager). We hebben nu een volledig nieuwe inrichting van deze dienst op basis van IBM Spectrum Protect Plus (SPP).
Medio februari 2018 is Interconnect voor het eerst in aanraking gekomen met dit product. Onze organisatie is als early adopter gevraagd om dit product te gaan testen gezien in verband met de bestaande TSM omgeving.
De back-up dienst waarvoor dit gebruikt wordt, is de “basis” back-up voorziening die in Interconnect’s standaard SLA zit. De vereisten waren in de basis relatief eenvoudig;
- het systeem dient een dagelijkse disaster recovery back-up te kunnen maken van virtuele servers, ongeacht het besturingssysteem wat hierop geïnstalleerd is.
- de back-ups mogen geen applicatie-aware of crash consistent back-ups zijn, omdat wij als infrastructuurbeheerders geen toegang tot deze vms hebben.
- Alle VM backups dienen direct cross-site opgeslagen te worden.
- De huidige TSM omgeving had een front-end capaciteit met ongeveer 130TB opgeslagen data, met een gemiddelde change rate van 15%.
We zijn gestart in het lab met versie 10.1, een single-server installatie om de basis functionaliteit te testen. De resultaten van deze test lieten zien dat de set-up van deze applicatie erg eenvoudig was. Ook waren we positief verrast door de technische inrichting van deze oplossing. Met name de keuze voor het filesystem (ZFS) op de vSNAP opslagservers was een positieve constatering.
De ondersteuning van VMware VM tags stelde ons in staat om via PowerCLI script VM’s automatisch toe te voegen aan SLA’s. Dit was een zeer welkome functie.
Om te controleren welke VM’s in welke SLA’s (back-up jobs) mee worden genomen, is ervoor gekozen om gebruik te maken van VM-tags. Ook onze andere back-up systemen (zoals Veeam) ondersteunen dit mechanisme. Hierdoor zijn we in staat volledig door middel van scripts te bepalen welke VM via welke back-up applicatie (en welke job of SLA) wordt meegenomen.
Get-Cluster "MAIN-LAB-CLUSTER" | Get-VM | ?{(Get-TagAssignment $_) -eq $null}| New-TagAssignment -Tag "spp SLA NAME"
Daarnaast leerden we dat SPP gebruik maakt van ZFS op de VSNAP, wat op zijn beurt gebruik maakt van VMware CBT en ZFS snapshots voor efficiënte restore points. Dit zorgt ervoor dat elke VM direct vanuit de back-up op te starten is en bij compleet verlies van de SPP server (configuratie) omgeving direct vanuit de repository VM te herstellen is.
Het product voelde weliswaar nog niet “af”, maar beterschap werd beloofd en samen met IBM is besloten een grotere testcase op te zetten. In de 2e lab test zijn we met diverse vSphere installatie versies (6.0/6.5) gaan testen. Inmiddels was ook versie 10.2 gelanceerd. In deze lab omgeving zijn onder meer cross-vCenter, applicatie-aware back-ups getest. Tevens zijn met name de verschillen in transport modes en de gedistribueerde architectuur getest. In deze lab omgeving liet de betrouwbaarheid en stabiliteit van de back-ups te wensen over. Deze issues zijn echter samen met IBM support onderzocht, wat resulteerde in tussentijdse hotfixes en patches.
Naast deze issues bleken er ook wat issues voort te komen uit onze eigen lab omgeving. Sindsdien is het systeem erg stabiel gebleken en zijn we over een langere periode grote hoeveelheid test VM’s met verschillende load dagelijks gaan back-uppen. Ondertussen werd er toegelegd op het ontwerp van de productie omgeving. Het design is gemaakt door middel van beschikbare documentatie, blueprints en sizing guides die direct beschikbaar waren bij IBM.
Ondertussen waren de lab resultaten erg positief. De stabiliteit was meer dan prima te noemen. Al bleef de performance achter op de verwachting. Dit was te verklaren doordat het onderliggende netwerk niet representatief was ten opzichte van het productienetwerk.
De componenten binnen een gedistribueerde Spectrum Protect Plus omgeving zien er als volgt uit:

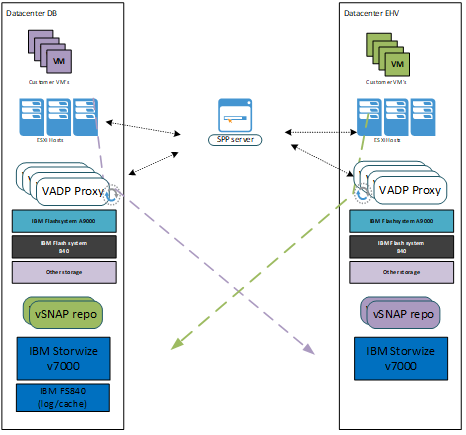
Hierbij wordt data vanuit de productie storage in het ene datacenter direct naar de vSNAP server in het andere datacenter geback-upt. Nadat de productie set-up uitvoerig getest is, zijn de eerste productie VM’s opgenomen in de SLA’s van Spectrum Protect Plus.
Onze ervaringen bij de start van de implementatie:
- De stabiliteit was vanaf het begin prima, maar de performance bleef achter bij onze verwachtingen;
- Performance bottlenecks waren lastig te onderzoeken door de manier waarop logfiles gemaakt worden;
- Uitsluiten van het Quiesing mechanism bij gebruik van VMware tags bleek niet altijd even goed overgenomen te worden in de properties van de individuele vm’s;
- Kleine afwijkingen opgemerkt en doorgegeven aan IBM support; dit waren echter geen show stoppers.
We zijn verder gegaan met de implementatie en hebben de performance issues verder onderzocht.
De aantallen proxies zijn getest met de settings “numbers of VM’s per host” in combinatie met het maximum aantal taken per VSNAP. Dit leverde ons een goed beeld op van het aantal te gebruiken VADP proxies per datacenter, echter nog steeds geen grote performance impact. De oorzaak van de performance issues was terug te leiden naar de performance penalty bij zfs. Deze is bij data deduplicatie in de praktijk vaak hoger dan verwacht. Hierdoor is besloten data deduplicatie in onze omgeving niet te gebruiken.
Conclusie: Op dit moment zijn we enkele maanden verder, is versie 10.1.3 update 1 inmiddels uit en zonder enig probleem in productie genomen. De TSM infrastructuur is inmiddels volledig uitgefaseerd.
Tussentijdse updates hebben laten zien dat IBM hard heeft gewerkt aan de technische kant van het systeem, met name het schedulen van taken per VADP proxy. Hieraan gekoppeld het moment dat VMware snapshots worden gemaakt, heeft ervoor gezorgd dat het systeem bijzonder goed “zelf” zijn resources regelt.
Vandaag de dag kunnen we trots zijn op ongeveer duizend VMs die dagelijks geback-upt worden via SPP. Dit resulteert in ons geval aan totaal +/- 76 TB aan data en een dagelijkse data throughput van gemiddeld 4~5 TB per DC per nacht.
Onderstaande afbeelding toont een overall success rate van maar liefst 92.55% (dit is inclusief test jobs en systeem capaciteits-waarschuwingen).

Onze ervaring en of aanbevelingen naar aanleiding van dit project zijn:
- Performance issues of connectivity issues hebben in de meeste gevallen te maken met eigen infrastructuur;
- GUI is eenvoudig, en administrators kunnen er snel mee aan de slag;
- Updates en patches installeren is erg eenvoudig en goed gedocumenteerd;
- Er is veel technische informatie beschikbaar;
- IBM heeft goede en kundige support die korte lijnen heeft met developer;
- Sizing guide klopt aardig, maar het succes van de applicatie is sterk afhankelijk van eigen infrastructuur.
Al met al een mooi project om te doen en een mooi product om mee te werken.
U kunt natuurlijk contact met ons opnemen hierover via info@interconnect.nl.
Plaats reactie